NVIDIA GPU selector



Compute
AI training and inferencing, data analytics, HPC

General Purpose
Visualization, rendering, AI, virtual workstations

High-Density VDI
Virtual applications, virtual desktops, virtual workstations





| GPU | L4 | RTX PRO 4500 Blackwell SE | A16 | A40 | L40S | A100 PCIe | SXM4 | H100 PCIe | H100 SXM5 | H100 NVL | H200 SXM5 | H200 NVL | RTX PRO 6000 Blackwell SE | B200 | B300 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Architecture | Ada Lovelace | Blackwell | Ampere | Ampere | Ada Lovelace | Ampere | Hopper | Hopper | Hopper | Hopper | Hopper | Blackwell | Blackwell | Blackwell |
| Card chip | AD104 | GB 203 | GA107 | GA102 | AD102 | GA100 | GH100 | GH100 | GH100 | GH100 | GH100 | GB202 | B200 | B300 |
| # CUDA cores | 7 680 | 10 496 | 4x 1 280 | 10 752 | 18 176 | 6 912 | 14 592 | 16 896 | 16 896 | 16 896 | 16 896 | 24 064 | TBA | TBA |
| # Tensor cores | 240 | 328 | 4x 40 | 336 | 568? | 432 | 456 | 528 | 528 | 528 | 528 | 752 | TBA | TBA |
| GPU memory | 24 GB | 32 GB | 4x 16 GB | 48 GB | 48 GB | 80 | 40 GB | 80 GB | 80 GB | 94 GB | 141 GB | 141 GB | 96 GB | 192 GB | 288 GB |
| Memory technology | GDDR6 | GDDR7 | GDDR6 | GDDR6 | GDDR6 | HBM2 | HBM3 | HBM3 | HBM3e | HBM3e | HBM3e | GDDR7 | HBM3e | HBM3e |
| Memory throughput | 300 GB/s | 896 GB/s | 4x 200 GB/s | 696 GB/s | 864 GB/s | 1 935 | 2 039 GB/s | 2 TB/s | 3.3 TB/s | 3.9 TB/s | 4.8 TB/s | 4.8 TB/s | 1.6 TB/s | 8 TB/s | 10 TB/s |
| FP64 (TFlops) | 0,49 | — | 0,271 | 1,179 | 1,413? | 9.7 | 26 | 30 | 30 | 34 | 30 | — | TBA | TBA |
| FP64 Tensor (TFlops) | — | — | — | — | — | 19.5 | 51 | 60 | 60 | 67 | 60 | — | 37 | 1.2 |
| FP32 (TFlops) | 30,3 | 51 | 4x 4,5 | 37,4 | 91,6 | 19.5 | 51 | 60 | 60 | 67 | 60 | 126 | 75 | 72 |
| TF32 Tensor (TFlops) | 120* | 203 | 4x 18* | 150* | 366* | 312* | 624* | 756* | 989* | 835* | 989* | 835* | 251 | 2 200* | 2 200* |
| FP16 Tensor (TFlops) | 242* | 406 | 4x 35,9* | 299* | 733* | 312* | 624* | 1 513* | 1 979* | 1 671* | 1 979* | 1 671* | 503.8 | 4 500* | 4 500* |
| INT8 Tensor (TOPS) | 485* | 811 | 4x 71,8* | 599* | 1 466* | 624* | 1 248* | 3 026* | 3 958* | 3 341* | 3 958* | 3 341* | 1 007.6 | 9 000* | 280* |
| FP8 Tensor (TFlops) | 485* | 811 | — | — | 1 466* | — | 3 026* | 3 958* | 3 341* | 3 958* | 3 341* | 2 015.2* | 9 000* | 9 000* |
| FP4 Tensor (TFlops) | — | 1 600 | — | — | — | — | — | — | — | — | — | 4 030.4* | 18 000* | 18 000* |
| Multi-Instance GPU | vGPU | 2 instances | vGPU | vGPU | vGPU | 7 instances | 7 instances | 7 instances | 7 instances | 7 instances | 7 instances | 4 instances | TBA | TBA |
| NVENC | NVDEC | JPEG engines | 2 | 4 | 4 | 3 | 3 | 4 | 8 | 1 | 2 | 3 | 3 | 4 | 0 | 5 | 5 | 0 | 7 | 7 | 0 | 7 | 7 | 0 | 7 | 7 | 0 | 7 | 7 | 0 | 7 | 7 | 4 | 4 | 4 | TBA | TBA |
| GPU link | PCIe 4 | PCIe 5.0 | PCIe 4 | NVLink 3 | PCIe 4 | NVLink 3 | NVLink 4 | NVLink 4 | NVLink 4 | NVLink 4 | NVLink 4 | PCIe 5 | NVLink 5 | NVLink 5 |
| Power consumption | 40-72W | 165 W | 250 W | 300 W | 350 W | 300 W | 400 W | 350W | 700 W | 400 W | 700W | 600W | 600 W | 1 000W | 1 400W |
| Form factor | PCIe gen4 1-slot LP | PCIe gen5 1-slot FHFL | PCIe gen4 2-slot FHFL | PCIe gen4 2-slot FHFL | PCIe gen4 2-slot FHFL | SXM4 | PCIe gen4 2-slot FHFL | PCIe gen5 2-slot FHFL | SXM5 card | PCIe gen5 2-slot FHFL | SXM5 card | PCIe gen5 2-slot FHFL | PCIe gen5 2-slot FHFL | SXM5 card | SXM5 card |
| Spec sheet | spec sheet | Datasheet | spec sheet | spec sheet | spec sheet | spec sheet | spec sheet | spec sheet | spec sheet | spec sheet | spec sheet | spec sheet | spec sheet | spec sheet |
| Announcement | 2023 | 2026 | 2021 | 2020 | 2023 | 2020 | 2022 | 2022 | 2024 | 2023 | 2023 | 2025 | 2024 | 2025 |
| Availability | ||||||||||||||
| GPU | L4 | RTX PRO 4500 Blackwell Server Edition | A16 | A40 | L40S | A100 SXM4 | PCIe | H100 PCIe | H100 SXM5 | H100 NVL | H100 | H200 SXM5 | H200 NVL | RTX PRO 6000 Blackwell Server Edition | B200 | B300 |
1) preliminary numbers
2) the total power consumption of CPU, GPU and memory on the superchip
Availability: ![]() – good (on stock or 4-6 weeks),
– good (on stock or 4-6 weeks), ![]() – medium (around 10 weeks),
– medium (around 10 weeks), ![]() – bad (15 weeks+),
– bad (15 weeks+), ![]() – not available
– not available
- A16, A100, V100, RTX4000 Ada (CTU Prague)
- A100, L40s (NVIDIA)
- DGX H100, DGX B200 (NVIDIA)
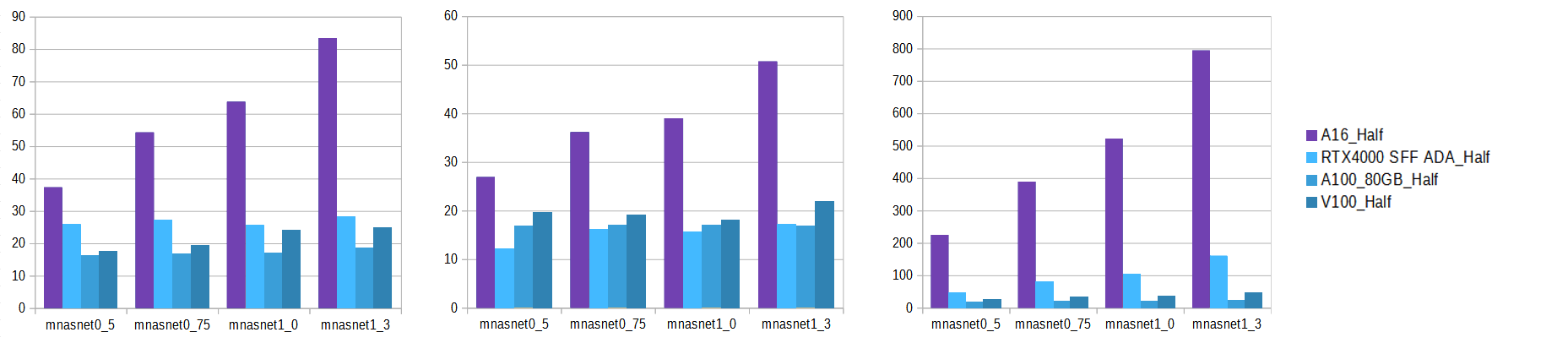
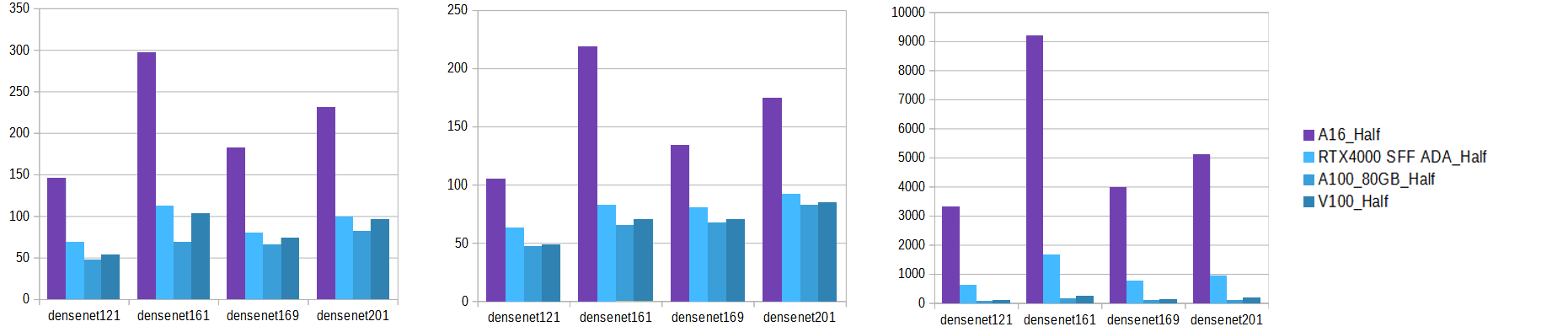
NVIDIA A16, A100, V100, RTX4000 Ada by CTU FEE in Prague
PyTorch training time GPU comparison
MnasNET
Time (lower is better)
ResNET
Time (lower is better)

DesNET
Time (lower is better)
NVIDIA A100 vs. NVIDIA L40s application benchmarks
| Benchmarks | # GPUs | Precision | Metric | A1001 | L40S | L40S/A100 | |
|---|---|---|---|---|---|---|---|
| DL Training | GPT 7B2 (GBS=512) |
8 | FP16/FP8 | Samples/sec | 13.5 | 15.7 | 1.2x |
| ResNet-50 V1.5 Training (BS=32) |
1 | FP16 | Images/sec | 2707 | 2748 | 1.0x | |
| BERT Large Pre-Training Phase 1 (BS=128, seq 512) |
1 | FP16 | Sequences/sec | 579 | 472 | 0.8x | |
| BERT Large Pre-Training Phase 2 (BS=8, seq 512) |
1 | FP16 | Sequences/sec | 152 | 161 | 1.1x | |
| DL Inference | ResNet-50 V1.5 Inference (BS=32) |
1 | INT8 | Images/sec | 23439 | 34588 | 1.5x |
| BERT Large Inference (BS=8, seq 128) |
1 | INT8 | Sequences/sec | 3011 | 4090 | 1.3x | |
| BERT Large Inference (BS=8, seq 384) |
1 | INT8 | Sequences/sec | 1116 | 1598 | 1.4x | |
| BERT Large Inference (BS=128, seq 128) |
1 | INT8 | Sequences/sec | 5065 | 5273 | 1.0x | |
| BERT Large Inference (BS=128, seq 384) |
1 | INT8 | Sequences/sec | 1445 | 1558 | 1.1x | |
| Stable Diffusion | Demo Diffusion 2.1 Inference (BS=1, 512x512) |
1 | FP16 | Pipeline Latency (ms) | 827 | 743 | 1.1x |
| Demo Diffusion 2.1 Inference (BS=1, 1024x1024) |
1 | FP16 | Pipeline Latency (ms) | 4186 | 3582 | 1.2x | |
| Stable Diffusion XL (BS=1, PyTorch native) |
1 | FP16 | Pipeline Latency (ms) | 10450 | 11194 | 0.9x | |
| Stable Diffusion XL (BS=1, PyTorch optimized) |
1 | FP16 | Pipeline Latency (ms) | 7353 | 7382 | 1.0x | |
| Stable Diffusion XL (BS=1, TRT optimized) |
1 | FP16 | Pipeline Latency (ms) | 5251 | 5547 | 1.0x | |
| DL Inference | GPT2 Inference (BS=1) |
1 | FP16 | Samples/sec | 1333 | 1828 | 1.4x |
| GPT2 Inference (BS=32) |
1 | FP16 | Samples/sec | 6502 | 7578 | 1.2x | |
| GPT2 Inference (BS=128) |
1 | FP16 | Samples/sec | 6850 | 6701 | 1.0x | |
| DLRM (BS=1) |
1 | TF32 | Records/sec | 6495 | 9458 | 1.5x | |
| DLRM (BS=64) |
1 | TF32 | Records/sec | 319131 | 517072 | 1.6x | |
| DLRM (BS=2048) |
1 | TF32 | Records/sec | 4668287 | 6980429 | 1.5x | |
| ViT Inference (BS=32, seq 224) |
1 | FP16 | Samples per Second | 1556 | 1477 | 1.0x | |
| ViT Inference (BS=32, seq 384) |
1 | FP16 | Samples per Second | 501 | 404 | 0.8x | |
| HF Swin Base Inference (BS=1,Seq 224) |
1 | INT8 | Samples per Second | 633 | 920 | 1.5x | |
| HF Swin Base Inference (BS=32,Seq 224) |
1 | INT8 | Samples per Second | 2998 | 3564 | 1.2x | |
| HF Swin Large Inference (BS=1,Seq 384) |
1 | INT8 | Samples per Second | 411 | 345 | 1.2x | |
| HF Swin Large Inference (BS=32,Seq 384) |
1 | INT8 | Samples per Second | 478 | 570 | 0.8x |
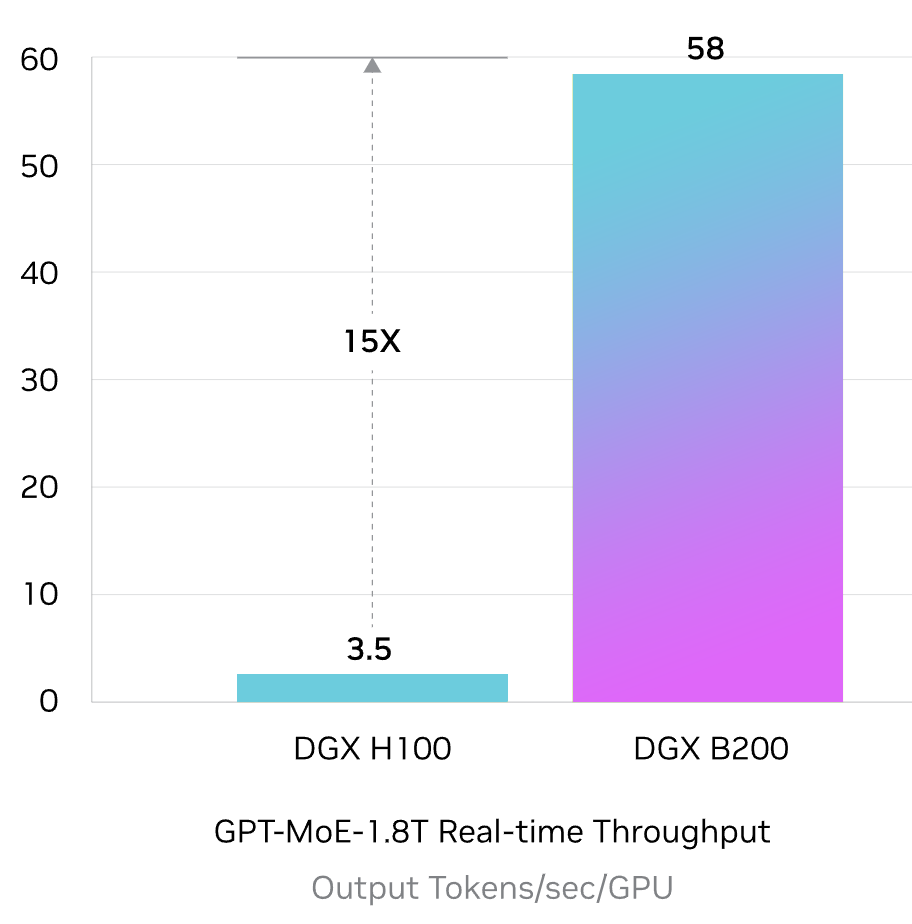
NVIDIA B200 GPUs theoretical performance in DGX systems